

Simple Data Fix Language (SDFL)
Il y a de cela quelques années, j’avais le goût de créer un langage de programmation. Pas parce que le monde a besoin de plus de langages, mais bien pour me pratiquer, en tant que programmeur, à développer du code en sortant de ma zone de confort. Le résultat, c’est le Simple Data Fix Langage ou SDFL pour les intimes 😛 Aujourd’hui, j’aimerais vous le présenter. Peut-être que ça vous donnera le goût d’essayer d’en créer un?
À quoi il sert ton langage?
Le langage SQL en est un simple. Par contre, quand on arrive avec des cas plus complexes, ça devient pas mal propriétaire, signifiant qu’une requête valide sur une BD Oracle ne le sera potentiellement pas sur MySQL ou SQL Server. L’idée par de là. Est-ce qu’on peut avec un langage au dessus de SQL avoir une syntaxe unique qui se compilerait en SQL propriétaire?
De plus, il peut arriver dans certains systèmes avec des flux de travail complexes que certaines données de production nécessitent des mises à jour par programmation. On appelle ça un « data fix ». Traditionnellement, les devs produisent la requête au format SQL, puis un DBA ou une personne ayant accès à l’environnement de production va exécuter la requête pour réparer les données. Ceci étant dit, je n’ai pas vu 2 entreprises avec les mêmes standards quant à comment on conserve ces scripts, ni comment ils sont produits, ni comment ils sont packagés pour le déploiement.
SDFL se veut une solution à tout ça. Une syntaxe unique avec une structure de fichiers standardisée.
Cas #1 – Fix simple
Voici un exemple, observons ce qu’il se produit :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/** * Description du package... * @author Sylvain Cloutier */ in package 2019NOV20PM; /** * Description du fix en particulier * @author Sylvain Cloutier */ create datafix DataFixName - Data fix description; import myFile.xlsx into MY_TABLE using template #1 -> MY_COLUMN_1, #2 -> MY_COLUMN_2, #3 -> MY_COLUMN_3; |
En ignorant les commentaires, la première ligne in package 2019NOV20PM; permet de créer un package de plusieurs scripts. Disons que ce package est prévu pour être déployé en production le 20 novembre 2019 en PM. Puis, la deuxième ligne create datafix DataFixName - Data fix description; permet un définir un script destiné à fixer une donnée. On peut s’imaginer que l’utilisateur va avoir ouvert un billet de service dans un système de billetterie comme Jira. La ligne, dans un cas plus réel, pourrait devenir :
|
1 |
create datafix 54287 - Mettre à jour le statut de l'employé; |
Ou 54287 serait le ID du billet Jira.
Ça… c’est pour la standardisation de la structure. On verra plus bas le résultat en SQL de ces lignes. La dernière opération de l’exemple ci-dessus, c’est une importation de données depuis le format Excel dans une table. Corrigez-moi si je me trompe, mais il n’y a pas de standard SQL pour faire ça. Donc, on prend le fichier myFile.xlsx et on charge son contenu dans la table MY_TABLE, en mappant les colonnes par leur position sur une colonne de la table (colonne #1 du fichier Excel dans MY_COLUMN_1 de la table MY_TABLE, etc.).
Compiler le script
Puis, on compile :
|
1 |
sdfl exemple.sdf |
Par défaut, parce que le langage n’est pas du tout complété (c’est plus une expérience qu’un véritable projet), le compilateur sera celui d’Oracle. Donc, ça prend notre fichier source SDFL et ça le compile dans un package destiné à être exécuté sur Oracle avec SQL*Plus :
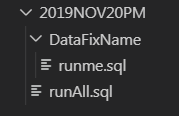
On voit donc que le compilateur a créé un dossier qui porte le nom du package définit en SDFL, puis un sous-dossier par « datafix » définit avec la commande create datafix. Un fichier runAll.sql est créé pour avoir un seul point d’entrée pour l’exécution de ce package. Ce fichier contient la liste des appels aux runme.sql, en utilisant la syntaxe SQL*Plus :
|
1 |
@@DataFixName\runme.sql |
Finalement, le runme.sql contient le code SQL du datafix. Dans l’exemple ci-dessus, c’était un import de fichier Excel. Le résultat est le suivant :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
INSERT INTO MY_TABLE ( MY_COLUMN_1, MY_COLUMN_2, MY_COLUMN_3) VALUES ( 'Test valeur 1', 's1010', 'w83838'); INSERT INTO MY_TABLE ( MY_COLUMN_1, MY_COLUMN_2, MY_COLUMN_3) VALUES ( 'Test valeur 2', 'a72', 'e91929'); INSERT INTO MY_TABLE ( MY_COLUMN_1, MY_COLUMN_2, MY_COLUMN_3) VALUES ( 'Test valeur 3', 's982', 'qw92309'); |
Rien de bien compliqué 😛 Mais là est tout l’avantage. On pourrait penser à des commandes comme include some-other-file.sdf; pour permettre de bien séparer les scripts par fichiers indépendants, ou encore une requête comme celle ci :
|
1 2 3 4 5 |
create datafix DataFixName - Data fix description; insert into MY_TABLE using template "My value 1" -> MY_COLUMN_1, "My value 2" -> MY_COLUMN_2 only if not exist; |
only if not exist pourrait être compilé, par exemple, en un insert select imbriqué qui valide avant l’insertion que la table MY_TABLE ne contient pas déjà une ligne avec ces données.
Et le code?
Disponible ici! C’est codé en Java en utilisant la technique du test driven development pure, signifiant que je n’ai écrit aucune ligne de code avant d’avoir écrit le test qui valide que cette ligne sera correcte. Je vous invite aussi à consulter le dépôt original qui contient le Wiki expliquant l’architecture. Si c’est quelque chose qui vous intéresserait, je serais ouvert à faire un article qui explique comment on crée un langage comme SDFL 🙂
Conclusion
Aujourd’hui, vous avez découvert qu’il est possible de créer facilement un langage de programmation qui peut avoir une utilité réel. J’espère que ça vous donnera le goût de cloner le dépôt Git et d’essayer de comprendre le code et les tests. J’espère encore plus vous avoir donné le goût de vous en créer un vous-même. Si c’est le cas, envoyez-moi votre lien GitHub 😀 Je suis sûr que certains seront très créatifs.
Comme d’hab, merci de partager nos articles 🙂 Vous pouvez utiliser les boutons de partage ci-dessous. Ça prend 1 seconde et ça nous aide à garder le focus en voyant le nombre de vue grimper. C’est notre seule paie! Vous êtes notre gaz.
Cheers!
Commentaires
Laisser un commentaire