

L’importance de l’abstraction
En début de carrière, je me souviens avoir eu beaucoup de difficultés à comprendre l’importance de l’abstraction dans le code. Le plus irritant, c’était de ne pas pouvoir naviguer dans le code dans l’EDI en faisant ctrl + click sur le nom d’une méthode parce qu’on arrivait sur l’interface. Il fallait faire « Go to implementations… » et là, surprise! Y’en as plusieurs! Pas le choix de jouer au compilateur dans ta tête pour savoir c’est laquelle la bonne. Pire encore, des fois c’était la hiérarchie des classes qui avait plusieurs niveaux, au point où tu sais plus où tu es…
Mais Sylvain, c’était quoi ce code de m…-là?!
J’ai eu la « chance » de débuter ma carrière dans du code legacy. De Java 1.1 à Lotus Notes, en passant par du Netscape SuiteSpot, l’ancêtre de Nodejs. Même du Vb5… Bref.
Je dis « chance » ici parce que certains trouveront probablement qu’il n’y a aucun intérêt à faire du Struts sur Java 1.4, l’ère pré-générique, en début de carrière, mais ça m’a permi de constater ce que les erreurs au niveau de l’architecture et de la conception peuvent avoir comme impact 30 ans plus tard. J’ai pu aussi constater ce que ça coûte à maintenir en place, et aussi ce que ça coûte à réécrire. Tout ça m’a permi d’avoir mes premières tâches d’architecture organique vers mes 5 ans sur le marché du travail.
Puis, je suis tombé dans le piège de Dunning-Kruger et j’ai aussi fait des erreurs d’architecture et de conception. Parfois dans des projets personnels, dans des preuves de concept et parfois même en production.
Le couplage
Le couplage est un des principes fondamentaux de la programmation orientée-objet, mais il va au delà du code. On pourrait dire que le couplage se mesure par les interactions entre des composantes d’un système infomatique. Par exemple, un lien d’agrégation (utilise) ou de composition (a un) dans un diagrame de classes démontrent bien visuellement qu’il y a un lien entre deux classes.
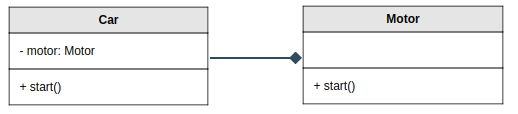
Mais on peut aussi retrouver un lien comme celui-ci entre deux serveurs. Par exemple, si un serveur d’API appelle un autre serveur d’API, il deviennent couplés assez fortement, au même titre que nos deux classes ci-dessus. Le principe peut donc s’appliquer pour tout ce qui a des interactions avec une autre composante.
Le problème avec le couplage, c’est qu’une une composante devient dépendante de l’autre. Tout changement au comportement de l’agrégée ( Motor) aura des répercussions sur la composite ( Car). Dans un exemple simple comme celui-ci, c’est plus difficile de comprendre l’impact qu’il pourrait y avoir, mais imaginez que Car et Motor ont plusieurs méthodes et que Car appelle les méthode de Motor un peu partout. On se retrouve donc avec un couplage très fort entre les deux classes. Imaginez qu’on aie créé la classe Motor en pensant que les voitures fonctionneraient toujours à essence.
L’abstraction
Pour casser complètement le lien fort entre deux composantes, il suffit d’ajoute une « couche » intermédiaire. Lorsqu’on parle de classes, ça se fait via une interface ou une classe abstraite. Lorsqu’on parle d’API, on pourrait voir un backend pour frontend, faisant office d’abstration de plusieurs services.

Une solution comme celle-ci, en ajoutant une couche entre les différents types de Motor et Car, on a la liberté d’assigner à Car n’importe quelle implémentation de Motor, sans qu’il n’y aie d’erreur de compilation. Visuellement, on peut constater qu’il n’y a plus de lien direct entre Car et l’implémentation des moteurs, contrairement à l’exemple précédent. En ajoutant le principe d’inversion de dépendances en faisant de l’injection de dépendences, ça nous amène même à avoir cette flexibilité à l’exécution.
Le risque réel
Un des fondements principaux de l’architecture logiciel est d’avoir un système qui va, au meilleur de nos connaissances, être à l’épreuve du futur, facile à maintenir et à faire évoluer. Il va de soit que le couplage est un de nos pires énnemis.
JavaScript avec ses modules ou C# avec Entity Framework offrent des façons faciles d’accéder aux données sans avoir la nécessité d’avoir une couche applicative réservée à cette fonction, comme une couche de dépôts (repositories). On voit pour C# l’utilisation du contexte de base de données depuis la couche responsable de l’exécution de la logique, ce qui couple fortement notre couche métier avec Entity Framework. On parlerait ici d’un couplage fort avec une librairie tierce.
Qu’arriverait-il s’il fallait changer de méthode d’accès aux données? Nous ne sommes pas à l’épreuve du futur et l’application devient difficile à faire évoluer.
Qu’arriverait-il s’il fallait ajouter des tests unitaires et mocker la base de données ou que la librairie aie une mise à jour avec des changements qui brise le code? L’application devient difficile à maintenir.
Quand abstraire?
Le plus important à comprendre, c’est qu’on veut la plupart du temps abstraire un comportement, donc des méthodes avec des algorithmes. Abstraire au niveau de l’état, comme les entities ou les objets d’affaires, est un peu plus natuel puisque les objets représentent des concepts d’affaires que nous connaissons.
Abstraire entre les couches applicatives
Dnas le cas d’un backend régulier, par exemple, la plupart du temps, il sont séparés en couches qui permettent de respecter au minimum le principe de responsabilité unique (SRP) au niveau de chacune d’entre elles (couche de logique, couche de persistence, etc.). En ajoutant une couche d’abstraction entre chacune des couches applicatives en plus de l’injection de dépendances, ceci permet de vraiment découpler nos couches de la technologie utilisée pour les développer. Par exemple, dans une application avec Spring Boot et Hibernate, nous pourrions avoir quelque chose comme :
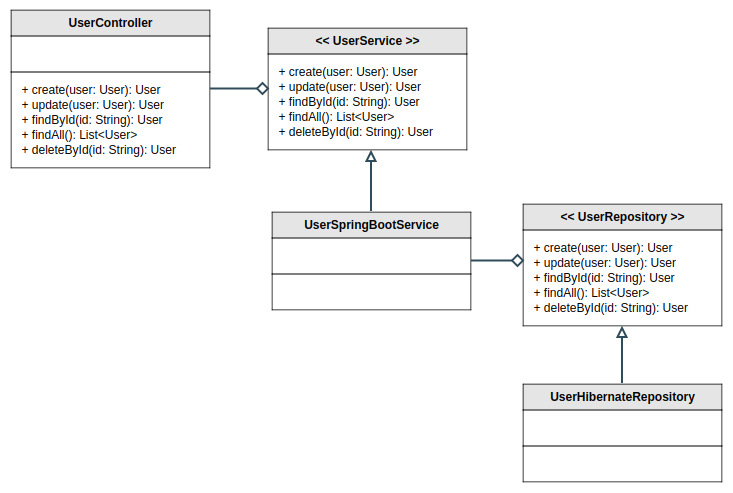
Le principal avantage d’abstraire au niveau des couches applicatives est que nous avons la liberté, sans coût supplémentaire, de changer l’une des couche pour une autre implémentation. Par exemple, en supposant que UserSpringBootService est externalisé dans un microservice externe, nous pourrions simplement créer un UserExternalServiceProxy et remplacer la logique par des appels API. L’autre avantage indéniable est au niveau de la flexibilité pour les tests unitaires. Cette architecture permet de mocker chacune des couches applications pour les tester indépendamment.
Abstraire au niveau des librairies tierces
Un autre cas où l’abstraction est primordial, c’est au niveau des librairies tierces. Le principe ici est de découpler complètement notre code applicatif avec le code en lien avec la librairie tierce pour limiter sa propagation dans le code et nous permettre de la changer si on se retrouve à avoir des limitations au niveau de l’implémentation.
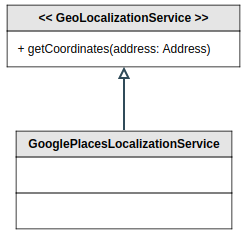
Abstraire au niveau du comportement
Comme troisième exemple, nous avons aussi la possibilité d’abstraire un comportement. Par exemple, si votre application doit envoyer une notification par courriel. Même sans avoir un besoin d’ajouter des modes de notificaiton comme SMS ou un push mobile, on peut être à l’épreuve du futur simplement en ajoutant cette couche d’abstraction. Dans l’exemple suivant, on peut même abstraire à deux niveaux, soit le comportement et la librairie tierce, pour un maximum de flexibilité à coût nul :
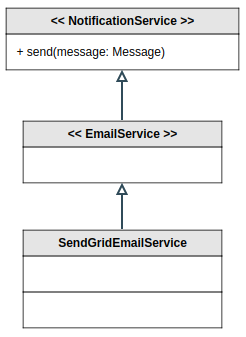
Note : SendGrid est un service tier d’envoi de courriels.
Quand limiter l’abstraction?
Comme je l’expliquais en introduction, l’abstraction peut aussi nous pénaliser parce qu’elle ajoute une certaine complexité au code. Ceci devient vrai lorsqu’on a plusieurs niveaux d’abstractions.
De plus, je ne recommanderais pas d’utiliser des classes abstraites avec des comportements définis qui seraient réutiliser par les sous-classes de cette classe abstraite. En supposant qu’on veuille rammener un comportement commun au niveau d’une classe abstraite et d’exposer ces comportements aux enfants de la classe via des méthodes protected, ceci nous complexifierait grandement la vie au niveau des tests unitaires. Par exemple :

En supposant que les contrôleurs enfants utilisent tous la méthode getUserLoggerFromRequest(), que cette dernière se trouve dans une classe abstraite et qu’elle soit protected, il nous faudra tester son comportement dans les suites de tests de tous les contrôleurs enfants, parce qu’une méthode qui n’est pas exposée publiquement doit être considérée comme faisant partie de l’algorithme principal. Il devient aussi extrêmement difficile de mocker le comportement de ladite méthode. Comme solution pour rendre le code plus facilement testable, on peut simplement changer le lien d’héritage pour un lien d’agrégation, tout en gardant notre abstraction :

De cette façon, nous découplons la stratégie pour récupérer l’utilisateur authentifié depuis la requête, nous nous permettons de mocker le service pour tester les contrôleurs indépendamment et nous avons aussi la possibilité de tester le SpringBootHttpRequestService de façon indépendante aussi.
Le meilleur des mondes!
Conclusion
Aujourd’hui, on a analyser en profondeur le concept d’abstraction. On a vu quels impacts le manque d’abstraction pouvait avoir sur la maintenabilité et la testabilité, mais aussi sur l’évolutivité de l’application. On a vu aussi que les concepts d’abstraction et de couplage sont étroitement liés ensemble et qu’ils peuvent s’appliquer sur plusieurs componsantes d’un système, et non seulement sur les classes entre elles. En espérant que cet article vous aide à comprendre l’importance de ce concept orienté-objet!
Si vous avez apprécié, n’hésitez pas à partager dans vos réseaux sociaux et avec vos collègues!
Cheers.
Commentaires
Laisser un commentaire